
요즘 세미나를 듣거나, 기술 블로그를 보면 Iceberg를 많이 사용하는 것 같다.
지금 회사에서도 Iceberg를 도입해서 운영 단계로 넘어온 상태이다.

데이터레이크라고 해서 대규모, 다양한 유형의 데이터를 한 곳에 모아서 사용하게 되면서
이에 적합한 테이블 포맷인 Iceberg를 더 많이 사용하게 되는 것 같다.
Apache Iceberg 란?.
Iceberg는 넷플릭스에서 개발한 테이블 포맷이다.
spark, impala, hive, trino 등 다양한 엔진에서 사용할 수 있다.
Iceberg 테이블은 메타데이터를 파일 형태로 관리하기 때문에 좀 더 빠르고 효율적인 쿼리가 가능하다.
impala 테이블을 iceberg 포맷으로 만든다고 해보자.
sotred as iceberg 구문만 넣어주면 된다.
create table sunnytest.iceberg_test_1 (
id string comment '식별자ID'
, name string comment '이름'
)
partitioned by (base_date string)
stored as iceberg
tblproperties ('format-version'='2'
, 'external.table.purge'='false'
, 'gc.enabled'='false'
, 'write.delete.mode'='merge-on-read'
, 'write.update.mode'='merge-on-read'
, 'write.merge.mode'='merge-on-read'
, 'write.metadata.delete-after-commit.enabled'='true'
, 'write.metadata.previous-versions-max'='5'
, 'write.format.default'='parquet'
, 'write.parquet.compression-codec'='SNAPPY'
)
;
Apache Iceberg 주요 기능 및 사용하는 이유
관계형 데이터베이스 (RDB) 처럼 CRUD가 가능하다. 즉, 기존 하둡과는 다르게 데이터 변경이 발생할 때 일괄 적재가 필요없고, 변경분만 적재할 수 있다. row 단위로도 update, delete 가 가능하다.
또한, 주기적으로 스냅샷(snapshot)을 생성하기 때문에 내가 원하는 시점의 데이터로 복구할 수 있는 기능 (Time travel)도 가능하다.
Apache Iceberg 테이블 구조
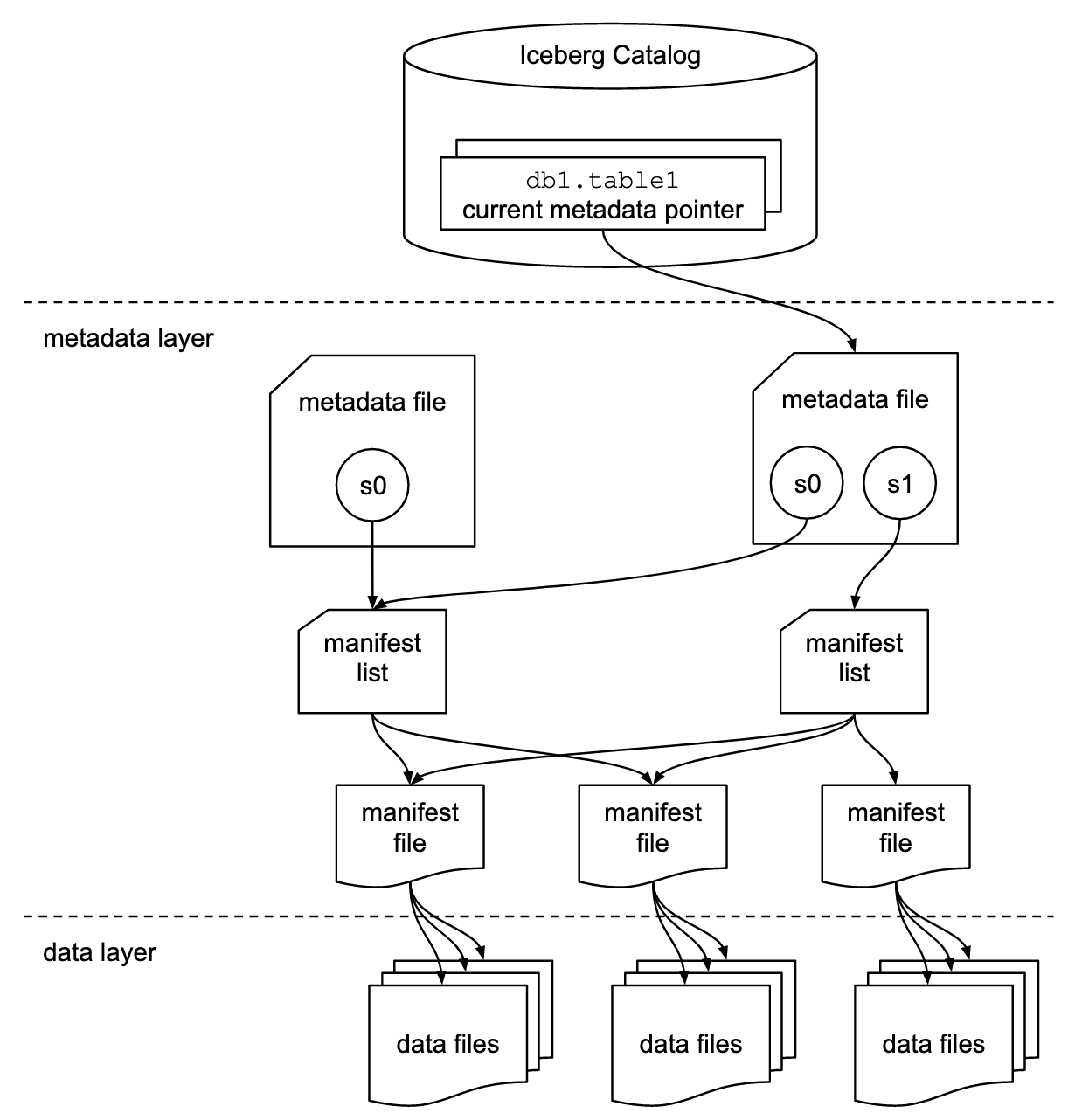
아이스버그 테이블은 3가지 영역으로 나눠볼 수 있다.
1) Catlog
현재 아이스버그 테이블의 메타데이터 파일을 찾을 수 있도록 해준다.
Hive Metastore를 사용하거나, AWS Glue 같은 카탈로그 서비스를 사용한다.
2) 메타데이터 영역
아이스버그 테이블의 메타데이터는 파일로 저장된다.
metadata 파일, 매니페스트 리스트 파일, 매니페스트 파일 3가지 파일이 있다.
3) 데이터 영역
실제 데이터가 파일에 저장된다. parquet, orc 등의 포맷으로 저장된다.
아이스버그 테이블을 조회하면 메타데이터 파일을 사용해서 필요한 데이터 파일만 읽게 된다.
table1/ => 테이블 디렉토리
|- metadata/ => metadata 디렉토리
| |- 00001-dssxf-xbv31f.metadata.json => metadata file
| |- 00002-adsxf-x12kgf.metadata.json
| |- 00003-jdxke-12dxgf.metadata.json
| |- snap-29c8-1-b103.avro => manifest list (파일명 : snap-{snapshot-id}-{sequence-number}-{****}.avro)
| |- snap-2fc3-2-16d3.avro
| |- dc2d-b103-3v.avro => manifest file
| |- x51x-12xv-12.avro
|- data/ => data 디렉토리
| |- base_date=2024-04-18/ => 파티션 디렉토리
| | |- 0000-5-123xd.parquet => data file
| | |- 0000-5-123xd-deletes.parquet => delete file
| | |- 0012-2-asx12.parquet
| |- base_date=2024-04-19/
| | |- 1235-1-12dxd.parquet
| | |- 0074-5-13xds.parquet
위에서 말한 메타데이터 파일, 데이터 파일은 HDFS, S3 등과 같은 저장소에 저장된다.
아이스버그 테이블이 저장된 디렉토리를 조회해보면, metadata 파일, data 파일이 저장되어 있는 걸 확인할 수 있다.
이 중에서 metadata 영역에 있는 파일들이 어떤 정보들을 담고 있는지 확인해보자!
metadata file
metadata 파일( metadata.json)은 해당 시점의 테이블 정보를 갖고 있다. 아이스버그 테이블에 insert, delete, update 등의 작업을 할 때마다 metadata.json 파일이 생성된다.
- location
- schema
- partition
- properties
- 현재 snapshot id
- snapshot 정보
- snapshot log (히스토리)
- metadata log (히스토리)
manifest list
매니페스트 목록(manifest list)은 어떤 스냅샷 파일을, 어떤 매니페스트 리스트를 참조하고 있는지에 대한 정보를 담고 있다.
- 스냅샷의 manifests file 리스트와 각 파티션 필드의 값 range를 함께 저장함.
- 스냅샷 파일이 있으면 time travel 기능으로 이전/이후 시점으로 데이터를 조회할 수 있다.
manifest file
매니페스트 파일 (manifest file)은 데이터 파일 목록을 갖고 있고, 파티션 및 컬럼 통계 정보 등을 갖고 있다.
- 데이터 파일 목록
- 해당 데이터 파일의 파티션 범위, 데이터 통계(최소값, 최대값 등)
앞으로도 iceberg 테이블을 사용할텐데,
iceberg 테이블을 사용하는 빅데이터 플랫폼에서 어떤 이슈들이 있는지,
어떤 포인트로 운영을 해야 하는지 잘 정리해두자 :)
'BigData 기술 > Hadoop' 카테고리의 다른 글
| Hadoop 클러스터 구축 과정 (4) | 2021.04.01 |
|---|---|
| DataNode failed volumes 원인 및 해결법 (8) | 2021.01.07 |
| [HDFS] 네임노드 구동과정 (Namenode Startup Process) (8) | 2021.01.05 |
| [HDFS] Block Pool 개념 정리 (8) | 2021.01.04 |
| [HDFS] 하둡 Balancer 과정 (1060) | 2020.07.20 |


댓글