HDFS는 데이터를 읽을 때 랜덤 엑세스가 아니고 Full scan을 한다. 그리고 update가 불가하며 append만 가능하다.
HBase는 HDFS에 있는 데이터를 랜덤 엑세스 하게 해주고 데이터를 update 할 수 있게 해준다.
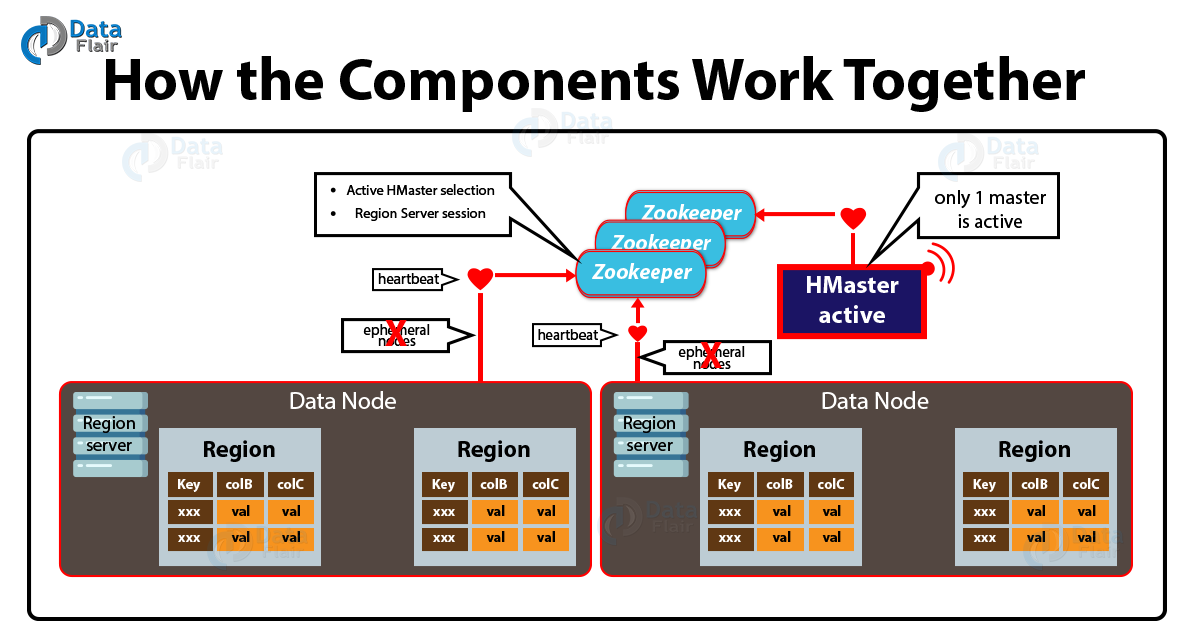
구성
Master
- HBase 설정파일과 Region Server들의 정보를 관리한다.
Zookeeper
- Master의 Active를 선정한다.
- Client는 META테이블(hbase:meta)을 갖고 있는 Region Server의 정보를 Zookeeper를 통해 얻는다.
- znode: /hbase/meta-region-server
- Master와 Region Server 모두 Zookeeper와 세션을 맺는다.
Region Server
- 하나 이상의 region들을 관리한다.
- hbase table 데이터를 관리한다.
hbase 테이블 데이터 (HFile)

- row key로 정렬되어 있다.
- 각각의 row key들은 특정한 region에 포함되어 있다.
- put/delete 작업 시 row key가 주어지면 row key를 가진 region을 관리하고 있는 region server를 찾는다.
hbase 테이블을 읽을 때 (Read)
- zookeeper에서 root region을 가리키는 region server를 찾는다.
- root region server로 부터 meta region을 가진 region server를 찾는다.
- meta region server로 부터 실제 요청된 region을 가지고 있는 region server를 찾는다.
hbase 테이블 데이터 업데이트 할 때 (Write)
HFile에 바로 쓰지 않는다.
- 변경사항들을 HFile에 바로 쓰지 않는다. HFile에 쓸 때는 반드시 row key로 정렬되어야 하기 때문이다.
- 또한 변경 사항을 매번 새로운 HFile에 쓰면 파일 개수가 많아져서 효율적이지 않다.
memstore에 쓰기 전에 WAL에 기록한다.
- 하지만 memstore는 메모리 영역이기 때문에 데이터가 손실될 위험이 있다.
- 그래서 memstore에 데이터를 쓰기 전에 업데이트 사항들을 WAL(Write-Ahead-Log)에 기록한다.
- region server에 문제가 생겨 memstore에 저장된 데이터가 날라갔더라도 WAL파일을 통해 복구할 수 있다.
- WAL파일은 edits들의 list를 가지고 있다. 하나의 edit이 put/delete 작업과 매칭된다. edit은 업데이트 사항 및 적용될 region 정보를 갖고 있다.
- edits파일은 시간 순서대로 정렬된다. (WAL파일 끝에서 append된다)
- WAL에 edits들이 쌓여 커지면 기존 WAL는 close되고 새로운 WAL파일이 생성되어 추가 edits들을 받는다. (rolling)
- 각 region server는 여러 개의 WAL파일을 갖는다. 그 중에서 활성화된 WAL파일은 오직 한 개 뿐이다.
WAL파일이 memstore(메모리영역)에 저장된다. (replay)
- 그래서 memstore라는 메모리 영역에 변경사항들이 저장된다.
- HFile과 같은 방법으로 데이터를 정렬하고 있다.
- memstore에 데이터가 충분히 쌓이면 전체 정렬된 데이터들은 HDFS 상에 새로운 HFile로 저장된다.
- 작은 데이터를 여러번 write 하는 것보다 하나의 대용량 write 하는 것이 더 효과적이다. (HDFS의 특성)
memstore에 데이터가 어느정도 쌓이면 HFile에 쓰인다. (Flush)
- memstore(메모리영역)의 데이터가 HFile형태의 데이터로 쓰인다. 비로소 디스크에 데이터가 저장되는 것이다.
참고링크
[HBase] WAL(Write Ahead Log)를 이용한 region 복구
* Apache HBase Write Path - Apache Hbase 는 hadoop의 HDFS를 기반으로 하는 database이다. HDFS 상의 파일은 생성 후에 오직 append 기능만을 제공하며 read 작업 수행 시 block 단위로 full-scan 이 이루어지..
paulsmooth.tistory.com
HBase Architecture - Regions, Hmaster, Zookeeper - DataFlair
HBase Architecture, what is HBase architecture, Regions, Hmaster, HBase Zookeeper, HBase meta data,Advantages of HBase Architecture.disadvantages of HBase
data-flair.training
Spark Read from & Write to HBase table using DataFrames
Is it possible to manipulate an unstructured data using a structured API ?
medium.com
'BigData 기술 > HBase,Phoenix' 카테고리의 다른 글
| Phoenix 연결방식 차이 (Thick / Thin) (4) | 2021.11.19 |
|---|---|
| HBase Start Process (HBase 2.2) - Region Assign (4) | 2021.09.08 |


댓글