개요
프로젝트 중 RDB를 사용하여 일부 데이터 처리가 필요하다고 한다.
이를 위해 RDB 중에 가벼운 postgres로 구성하기로 했다.
수집노드 2대를 활용하여 master-slave로 이중화 구성을 했다.
- 이왕 하는거 이중화하여 failover 구성
- 쿼리작업 분리를 통해 성능향상 기대
아키텍쳐

1) postgreSQL DB server
postgreSQL 는 오픈소스 RDBMS이다.
master와 slave
DB 복제는 아래와 같은 구성으로 할 수 있다. master에서 read/write 쿼리작업을 하고, slave는 read 쿼리만 수행한다.
프로젝트에서는 single-master / slave node 형상으로 구성한다.
- single-master / slave nodes
- multi-master / slave nodes

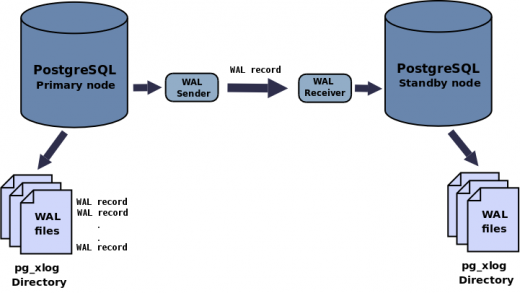
WAL 파일
복제는 master가 WAL(Write-Ahead-Log) 파일을 쓰고 slave에 전송하는 과정이다.
WAL 파일에는 DB의 변경 내역을 기록한다. MySQL의 binlog 파일이라고 보면 될 것 같다.
Log-shipping / Streaming 복제방식
WAL 파일 자체를 전송하는 것은 Log-shipping 방식이고, WAL 내용을 전송하는 것은 streaming 방식이다.
그래서 streaming 방식을 사용하면 master에서wal sender프로세스가 돌고, slave에서는wal receiver프로세스가 돈다.
프로젝트에서는 streaming 방식으로 복제하기로 한다.
- 전송 시간을 줄일 수 있기 때문에 delay가 줄어든다.
- Log-shipping은 async 방식만 가능하지만, streaming은 async와 sync 방식 모두 가능하다. (default는 async)
- sync : slave까지 제대로 복제됐는지 확인한 후에 commit이 된다. 데이터 손실을 막을 수 있다. 대신 commit 대기시간이 길어진다.
- async : slave까지 제대로 복제됐는지 확인하는 과정이 없다. 따라서 master 서버가 중간에 문제가 생겼는데 slave에 복제가 되지 않았다면 일부 데이터 손실이 발생할 수 있다. 대신 빠르다.
2) pgpool
haproxy 같기도 하면서 replication-manager 같기도 한 녀석이다.
pgpool을 사용한 이유는
- End Point를 단일화 하기 위해 사용한다.
- master DB, slave DB 각각 접속할 필요없이 pgpool에서 설정한 포트로 접속한다.
- failover를 자동으로 하기 위해 사용한다.
- load balancing을 하기 위해 사용한다.
- 단, 쓰기 작업 (ex. insert 쿼리)을 요청할 때는 master에만 접근한다.
이중화 구성하기
(1) master DB 구성
postgreSQL DB 서버를 설치하고, DB 데이터용 디렉토리를 만든다.
yum install postgresql-server
mkdir /data1/pgsql
passwd postgres
chown -R postgres.postgres /data1/pgsql
chmod 700 /data1/pgsqlmaster 노드에서 WAL 파일을 쓰는 작업에 관한 설정을 한다.
vim /data1/pgsql/postgresql.conf
listen_addresses = '*'
# archive 혹은 hot_standby
wal_level = hot_standby
# slave 노드에 WAL 파일을 전송할 때 사용하는 프로세스 개수
# slave 개수 + 1 만큼을 설정
max_wal_senders = 2- archive
- ??
- hot_standby
- standby 서버구성에 대한 정보도 WAL 파일에 기록한다. 그래서 슬레이브 서버 (standby)에 접속할 수도 있고, 읽기전용 쿼리를 수행할 수 있다.
- archive 작업도 수행한다.
외부 접속을 위한 설정을 한다.
vim /data1/pgsql/pg_hba.conf
# slave 노드 접속 허용
host replication replication 20.20.20.102/24 md5환경변수 설정을 한다.
su - postgres
vi ~/.bash_profile
PGDATA=/data1/pgsql
export PGDATA
source ~/.bash_profileDB를 초기화한다.
su - postgre
/usr/pgsql-11/bin/initdb /data1/pgsql
pg_ctl startpsql 명령어를 사용하여 CLI를 사용한다.
|
psql # 복제용 role 생성 CREATE ROLE replication WITH REPLICATION PASSWORD 'replica' LOGIN; # postgres 계정 비밀번호 생성 alter user postgres password 'postgres'; |
(3) slave DB 구성
postgreSQL DB 서버를 설치하고, DB 데이터용 디렉토리를 만든다.
|
yum install postgresql-server
mkdir /data1/pgsql passwd postgres chown -R postgres.postgres /data1/pgsql chmod 700 /data1/pgsql |
master DB 데이터를 가져온다. /data1/pgsql 디렉토리 하위를 확인하면 각종 디렉토리 및 파일이 생긴 것을 확인할 수 있다.
|
su - postgres
pg_basebackup -h cn01.kiki.org -D /data1/pgsql -U replication -v -P -X stream # 비밀번호 입력 (replica) |
slave 노드가 hot_standby 역할을 하도록 설정한다.
vim /data1/pgsql/postgresql.conf
|
hot_standby = on hot_standby_feedback = on |
slave 노드가 master 노드로 바뀌어야 할 때 (failover)를 위한 설정을 한다.
vim /data1/pgsql/recovery.conf
|
standby_mode='on' # master 노드의 정보를 적는다. primary_conninfo='host=cn01.kiki.org port=5432 user=replication password=replica' # slave노드에 trigger file이 있으면, slave가 master로 전환된다. trigger_file='/data1/pgsql/failover_trigger' |
slave DB를 기동한다.
|
pg_ctl start |
(4) master-slave 복제 테스트
master 확인
WAL 관련 프로세스를 확인해보자.wal sender process가 떠있는 것을 확인할 수 있다.
|
ps -ef | grep wal |
쿼리를 날려 master인지 확인해보자. recovery모드가 f(false)여야 master인 것이다.
|
select pg_is_in_recovery(); |
slave 확인
WAL 관련 프로세스를 확인해보자.wal receiver process가 떠있는 것을 확인할 수 있다.
|
ps -ef | grep wal |
쿼리를 날려 master인지 확인해보자. recovery모드가 t(true)여야 slave인 것이다.
|
select pg_is_in_recovery(); |
master에서 테이블을 생성하고 slave에서 읽어보자.
|
# master 서버 create table sunnytest ( c1 varchar(16) );
# slave 서버 \dt select * from sunnytest; |
슬레이브서버에서 insert 쿼리를 날리면 에러가 발생해야 한다. read-only이기 때문이다.
|
ERROR : cannot execute INSERT in a read-only transaction |
(5) pgpool 구성
cn01.kiki.org 서버에 pgpool을 구성한다. 원하는 서버에 구성하면 된다.
|
yum install pgpool-II mkdir /var/log/pgpool |
pgpool 설정을 한다.
vi /etc/pgpool-II/pgpool.conf
|
# pgpool 접근정보 listen_addresses = '*' port = 9999 enable_pool_hba = on
backend_hostname0 = 'cn01.kiki.org' backend_port0 = 5432 # load balancing 비중 설정 backend_weight0 = 1 backend_data_directory0 = '/data1/pgsql' backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = 'cn02.kiki.org' backend_port1 = 5432 # load balancing 비중 설정 backend_weight1 = 1 backend_data_directory1 = '/data1/pgsql' backend_flag1 = 'ALLOW_TO_FAILOVER'
logdir = '/var/log/pgpool'
replication_mode = off replicate_select = off insert_lock = off
replication_stop_on_mismatch = off
load_balance_mode = on
master_slave_mode = on master_slave_sub_mode = ‘stream’
sr_check_period = 10 sr_check_user = 'postgres' sr_check_password = 'postgres'
search_primary_node_timeout = 10 |
pgpool에서 master, slave 서버에 접근할 수 있도록 설정한다.
vi /etc/pgpool-II/pgpool.conf
|
host all all 20.20.20.101/24 trust host all all 20.20.20.102/24 trust |
pgpool을 기동한다.
|
pgpool -f /etc/pgpool-II/pgpool.conf -n -D -d > /var/log/pgpool/pgpool.log 2>&1 &
#pgpool 정지 pgpool stop |
pgpool을 통해 DB에 접속해보자. load balancing 설정을 해놨기 때문에 master에 접속됐다가 slave에 접속되는 것을 확인할 수 있다.
|
PGPASSWORD=postgres psql -h cn01.kiki.org -p 9999 -U postgres
# master, slave 노드정보 확인 show pool_nodes;
# 현재 접속된 노드 확인 # 로드밸런싱 설정을 해놔서 master, slave 왔다갔다 하면서 붙음 select inet_server_addr(); |
insert는 master에서만 가능하므로 알아서 master 노드에 붙는다.
|
PGPASSWORD=postgres psql -h cn01.kiki.org -p 9999 -U postgres -c "insert into sunnytest values ('hi')" |
(6) failover 설정
failover시, master 서버가 slave 서버한테 failover trigger 파일을 전송한다. 이 때 비밀번호 없이 전송하기 위해 ssh key 복사를 해준다.
cn01 노드 (postgres 계정으로 진행)
|
ssh-keygen ssh-copy-id postgres@cn02.kiki.org |
cn02 노드 (postgres 계정으로 진행)
|
ssh-keygen ssh-copy-id postgres@cn01.kiki.org |
failover_command를 작성한다. pgpool은 master의 장애를 감지하면 failover_command를 수행한다.
vi /etc/pgpool-II/pgpool.conf
|
failover_command = '/usr/share/pgsql/failover.sh %d %H /data1/pgsql/failover_trigger' |
failover_command는 아래 스크립트를 수행한다. master 서버에 장애가 생기면 slave 서버에게 trigger 파일을 전송하는 스크립트이다.
slave에 trigger 파일이 있으면 master로 전환한다. trigger 파일 경로는 slave의 /data1/pgsql/recovery.conf 에도 설정했다.
vim /usr/share/pgsql/failover.sh
|
if [ $# -ne 3 ] then echo "failover failed_node new_master trigger_file" exit 1 fi
FAILED_NODE=$1 # %d (장애생긴 DB의 node ID) NEW_MASTER=$2 # %H (새롭게 master가 될 DB의 호스트네임) TRIGGER_FILE=$3 # /data1/psql/failover_trigger
# Do nothing if standby server goes down if [$FAILED_NODE = 1] then echo "Standby Server is downed\n" >> /var/log/pgpool/failover.log exit 0 fi
echo "failover.sh FAILED_NODE:${FAILED_NODE}; NEW_MASTER:${NEW_MASTER}; at $(date)\n" >> /var/log/pgpool/failover.log
# failover trigger 파일을 slave(새로운 master) 노드에 전송한다. ssh -T postgres@$NEW_MASTER touch $TRIGGER_FILE exit 0 |
pgpool을 재시작 한다.
|
chmod 755 /usr/share/pgsql/failover.sh
pgpool stop pgpool -f /etc/pgpool-II/pgpool.conf -n -D -d > /var/log/pgpool/pgpool.log 2>&1 & |
(7) failover 테스트
master DB서버를 중지해보자!
cn01 노드 (postgres 계정으로 진행)
|
pg_ctl stop |
pgpool을 통해 DB 서버의 상태를 확인해보자. slave였던 cn02 노드가 master(primary)가 된 것을 확인할 수 있다.
cn01 노드의 status 값은 3(down)으로 바뀌었다.
|
PGPASSWORD=postgres psql -h cn01.kiki.org -p 9999 -U postgres -c "show pool_nodes;" |

cn02 노드 (new master)에서 /data1/pgsql 을 확인해보자. recovery.conf 파일이 recovery.done으로 변경되었다!
cn02 노드
|
ls -al /data1/pgsql |
cn01의 DB 서버를 다시 기동하고 다시 pgpool을 통해 DB 서버의 상태를 확인해보자.
cn01 노드 (postgres 계정으로 진행)
|
pg_ctl start PGPASSWORD=postgres psql -h cn01.kiki.org -p 9999 -U postgres -c "show pool_nodes;" |

cn01의 DB를 기동했는데도 여전히 cn01의 상태값이 3(down)이다. 왜냐하면 failover 후 자동으로 slave 로 추가되는 기능은 제공되지 않기 때문이다. 수동으로 해줘야 된다. 자동화를 하려면 pgpool 설정에서auto_failback을 활용해야 한다. 우선 수동으로 진행해본다.
새로운 slave가 된 cn01 노드에서 backup을 수행한다.
cn01 (new slave) 노드에서 진행
|
pg_ctl stop mv /data1/pgsql /data1/pgsql_back pg_basebackup -h cn02.kiki.org -U replication -p 5432 -D /data1/pgsql -v -X stream -P |
recovery.done 파일을 recovery.conf로 바꾼 후, recovery.conf 파일을 수정한다.
vim /data1/pgsql/recovery.conf
|
standby_mode='on' # new master 노드의 정보를 적는다. primary_conninfo='host=cn02.kiki.org port=5432 user=replication password=replica' trigger_file='/data1/pgsql/failover_trigger' |
pgpool한테 cn01 (new slave) 노드를 다시 붙인다.
|
pg_ctl start # pcp_attach_node -d <timeout> <pgpool ip/hostname> <port#> <DB ID> <DB PWD> <DB Node ID> pcp_attach_node -d 30 cn01.kiki.org 9898# postgres postgres 0 |
pcp_attach_node 를 수행하기 위해서 pgpool 설정을 사전에 해줘야 한다!
| echo "postgres:$(pg_md5 --username=postgres postgres)" >> /etc/pgpool-II/pcp.conf |
다시 pgpool을 통해 DB 서버의 상태를 확인해보자. cn01 (new slave)의 상태값이 제대로 나오는 것을 확인할 수 있다.
|
PGPASSWORD=postgres psql -h cn01.kiki.org -p 9999 -U postgres -c "show pool_nodes;" |

'기초 튼튼탄탄탄 > Database' 카테고리의 다른 글
| [mysql] 마스킹처리하는 함수 만들고 실행하기 (131) | 2021.01.08 |
|---|---|
| percona xtraDB cluster 설치하기 (12) | 2021.01.03 |
| mysqldump -p 옵션 비밀번호에 특수문자가 있을 때 (4) | 2020.04.18 |
| [mysql] 프로시저 생성/수정/실행 권한 주기 (4) | 2020.04.18 |
| 오픈소스 라이센스 GPL - xtrabackup 라이센스 (2) | 2020.02.12 |

댓글