개요
- spark-in-action 책을 보면서 공부한 내용을 정리한다.
- 스파크 스트리밍에서 kafka 토픽(orders) 데이터를 읽어서 kafka 토픽(metrics)에 결과를 전송해본다.
스파크 스트리밍이란? (Spark Streaming)
스파크 스트리밍(Spark Streaming)은 다양한 데이터 소스(Kafka, HDFS 등)로부터 데이터를 받아서 실시간 스트리밍 처리를 한다.
스트리밍 데이터를 구조적으로(테이블 형태) 사용하려면 Spark Structurec Streaming을 사용한다.
DStream
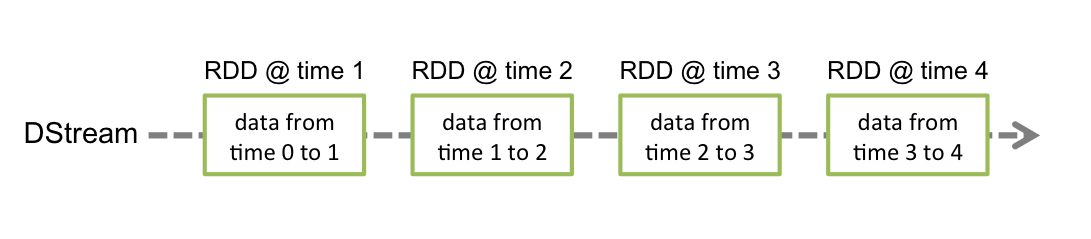
스파크 스트리밍에서 사용할 수 있도록 재구성한 데이터 형태를 Discretized Stream 혹은 DStream이라고 한다.
StreamingContext
- 스파크 스트리밍에서 사용하는 객체이다.
- DStream을 생성하는 다양한 메서드를 제공한다.
- 동일한 SparkContext 를 사용해서 StreamingContext 인스턴스를 여러 개 생성할 수 있다. 하지만 동일 JVM에서는 StreamingContext 를 한 번에 하나 이상 시작할 수 없다.
- 종료된 StreamingContext는 다시 시작할 수 없다. 대신 SparkContext 를 재사용해서 새로운 StreamingContext를 생성하여 사용한다.
미니배치
데이터를 작은 배치 단위로 잘라 각 노드에 분산/처리한다. 완전한 실시간이라기 보다는 마이크로배치 개념이다.
카프카란?

LinkedIn에서 개발된 분산 메시징 시스템이다.
Producer
특정 topic 메세지를 생성하여 Broker에게 전달한다.
Consumer
해당 topic을 구독하여 topic 메세지를 가져와 처리한다.
Kafka Cluster
- broker
카프카 서버
- zookeeper
카프카 브로커를 하나의 클러스터로 코디네이팅 한다.
broker 중에 leader를 선출하는 역할을 한다.
controller 라는 znode에서 leader로 선출된 broker id를 확인할 수 있다.
|
/usr/lib/zookeeper/bin/zkCli.sh get /controller |
Topic / Partition

- topic은 partition이라는 단위로 쪼개어져 클러스터의 각 서버들에 분산되어 저장된다.
- 고가용성을 위하여 복제(replication) 설정을 할 경우 이 또한 partition 단위로 각 서버들에 분산되어 복제된다.
- 장애가 발생하면 partition 단위로 fail over가 수행된다.
예제 코드
1) kafka topic (orders)에 데이터 전송하기
예제데이터 (orders.txt)
| 날짜 | 시간 | 주문 ID | 고객 ID | 주식 종목명 | 수량 | 가격 | 주식 매수(B), 매도(S) |
| 2016-03-22 | 20:25:28 | 1 | 80 | EPE | 710 | 51.00 | B |
streamOrders.sh
#!/bin/bash
BROKER=$1
if [ -z "$1" ]; then
BROKER="192.168.10.2:9092"
fi
cat orders.txt | while read line; do
echo "$line"
sleep 0.1
done | /usr/lib/kafka/bin/kafka-console-producer.sh --broker-list $BROKER --topic orders./streamOrders.sh dss01.nexr.com:9092,dss02,nexr.com:9092
2) spark streaming 으로 kafka topic (orders) 데이터 읽어서 kafka topic (metrics)에 전송하기
spark-shell 구동을 먼저 하자.
spark-shell --master local[4] --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.0, org.apache.kafka:kafka_2.11:1.0.0 --jars ./kafkaProducerWrapper.jar
spark streaming과 kafka를 연동하는 방식은 2가지가 있다.
1. Receiver Based
2. Direct (No Receiver)
아래 코드는 Receiver를 사용하는 방식이다.
그 다음 아래 코드를 수행한다.
import org.apache.spark._
import kafka.serializer.StringDecoder
import kafka.producer.Producer
import kafka.producer.KeyedMessage
import kafka.producer.ProducerConfig
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
// 스파크 스트리밍 컨텍스트 생성
val ssc = new StreamingContext(sc, Seconds(5))
// 카프카 설정을 Map 객체로 생성
val kafkaReceiverParams = Map[String, String](
"metadata.broker.list" -> "dss01.nexr.com:9092,dss02.nexr.com:9092")
// DStream을 생성한다.
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]
(ssc, kafkaReceiverParams, Set("orders"))
// 카프카 orders 토픽용 객체(스키마) 생성
import java.sql.Timestamp
case class Order(time: java.sql.Timestamp, orderId:Long, clientId:Long,
symbol:String, amount:Int, price:Double, buy:Boolean)
import java.text.SimpleDateFormat
// orders 카프카 토픽 데이터를 기반으로 데이터를 정제한다.
val orders = kafkaStream.flatMap(line => {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val s = line._2.split(",") // 20:25:28, 1, 80, EPE, 710, 51.00, B
try {
assert(s(6) == "B" || s(6) == "S") // B, S 만 포함될 수 있음. 다른 값이면 AssertionError 발생
// 필드 값을 파싱하여 Order 객체 기반의 List를 리턴
List(Order(new Timestamp(dateFormat.parse(s(0)).getTime()),
s(1).toLong, s(2).toLong, s(3), s(4).toInt, s(5).toDouble, s(6) == "B"))
}
// 형식이 안 맞으면 빈 List 리턴
catch {
case e : Throwable => println("Wrong line format ("+e+"): "+line._2)
List()
}
})
// (true, 매수주문건수) , (false, 매도주문건수)
val numPerType = orders.map(o => (o.buy, 1L)).reduceByKey((c1, c2) => c1+c2)
// ("BUYS", 매수주문건수 List) , ("SELLS", 매도주문건수 List)
val buySellList = numPerType.map(t =>
if(t._1) ("BUYS", List(t._2.toString)) // numPerType의 키가 true이면 매수 주문 건수를 기록
else ("SELLS", List(t._2.toString)) ) // false이면 매도 주문 건수를 기록
// key : 고객ID, value : 거래액(주문 수량 * 매매 가격) 으로 Pair DStream 생성
val amountPerClient = orders.map(o => (o.clientId, o.amount*o.price))
// key : 고객ID, value : 거래액 sum
val amountState = amountPerClient.updateStateByKey((vals, totalOpt:Option[Double]) => { // updateStateByKey(키-고객ID, 키의 상태값)
totalOpt match {
case Some(total) => Some(vals.sum + total) // 키의 상태가 이미 존재하면 상태값(total)에 새로 유입된 값의 합계(vals.sum)를 더한다.
case None => Some(vals.sum) // 이전 상태 값이 없으면 새로 유입된 값의 합계만 반환한다.
}
})
// 거래액 상위 1~5위 고객 (고객ID, 거래액)
val top5clients = amountState.transform(_.sortBy(_._2, false).map(_._1). //sortBy로 내림차순 정렬 -> map으로 번호는 제거
zipWithIndex.filter(x => x._2 < 5)) // zipWithIndex로 RDD의 각 요소에 번호를 부여 -> 상위 5개 남기고 필터링
// "TOP5CLIENTS", 거래액 상위 1~5위 고객 List
val top5clList = top5clients.repartition(1). // 모든 데이터를 단일 파티션으로 모은다.
map(x => x._1.toString). // 고객ID(x._1)만 남긴다(string)
glom(). // 파티션에 포함된 모든 고객 ID를 단일 배열로 묶는다.
map(arr => ("TOP5CLIENTS", arr.toList)) // 지표 이름과 고객 ID의 배열을 튜플로 만든다.
// 지난 1시간 동안 거래된 종목별 거래량 (종목명, 거래량 합)
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)).
reduceByKeyAndWindow((a1:Int, a2:Int) => a1+a2, Minutes(60))
// "TOP5STOCKS", 거래액 상위 1~5위 종목 List
val topStocks = stocksPerWindow.transform(_.sortBy(_._2, false).map(_._1).
zipWithIndex.filter(x => x._2 < 5)).repartition(1).
map(x => x._1.toString).glom().
map(arr => ("TOP5STOCKS", arr.toList))
// 최종 input data (DStream)
// "BUYS", "SELLS", "TOP5CLIENTS", "TOP5STOCKS"
val finalStream = buySellList.union(top5clList).union(topStocks)
// Producer 싱글톤 객체 (JVM별로 Producer 객체를 하나씩만 초기화)
// 카프카 브로커에 접속 -> KeyedMessage 객체의 형태로 구성한 메시지를 카프카 토픽으로 전송
// 별도 jar 파일 사용함 (spark-shell 실행시 jar 옵션 추가)
import org.sia.KafkaProducerWrapper
finalStream.foreachRDD((rdd) => {
rdd.foreachPartition((iter) => { // RDD 파티션별로 Producer를 하나씩 생성한다. (KafkaProducerWrapper는 JVM 별로 Producer 객체를 하나씩만 초기화 하는디..대치되는 개념이 아닌가?)
KafkaProducerWrapper.brokerList = "dss01.nexr.com:9092,dss02.nexr.com:9092"
val producer = KafkaProducerWrapper.instance // KafkaProducerWrapper 인스턴스 생성
iter.foreach({ case (metric, list) =>
producer.send("metrics", metric, list.toString) }) // input data를 metrics 카프카 토픽에 전송한다.(producer)
})
})
sc.setCheckpointDir("/spark-in-action/checkpoint")
ssc.start()- StreamingContext 생성
- 카프카 설정을 담은 Map 객체 생성
- 이를 기반으로 DStream 생성
- 카프카 orders 토픽용 객체(스키마) 생성
- "BUYS", "SELLS", "TOP5CLIENTS", "TOP5STOCKS" 에 해당하는 데이터 처리
- kafkaProducerWrapper.jar 에 포함된 클래스를 기반으로 kafka producer 인스턴스 생성하여 metrics 카프카 토픽에 데이터 전송
3) kafka topic (metrics) 데이터 확인하기
./kafka-console-consumer.sh --zookeeper dss01.nexr.com:2181,dss02.nexr.com:2181 --topic orders --from-beginning결론
- 스파크 스트리밍을 사용하기 위해 필요한 것들이 이런 게 있구나
- scala는 너무 어렵다
참고링크
https://livebook.manning.com/book/spark-in-action/chapter-6/1
'BigData 기술 > Spark' 카테고리의 다른 글
| RDS -> Spark(AWS EMR) -> Neo4jDB (4) | 2021.08.15 |
|---|---|
| [spark] spark에서 phoenix 테이블 읽고쓰기 (scala) (8) | 2021.01.14 |
| SPARK에서 저장소(HDFS, Hive 등)에 접근하는 방식 (745) | 2020.07.31 |
| [Spark] Spark 예제 - 데이터 로딩, 조인, 필터링, 정렬 (4) | 2020.07.10 |
| [Spark] Spark 예제 - 고객별 구매횟수, 구매금액 등 구해보기 (count, sum, sort) (4) | 2020.07.06 |


댓글